刚刚,Facebook把服务27亿人的AI硬件系统开源了
一直以来,社区对Facebook 的硬件研究比较关注。在今日的开放计算项目全球峰会上,Facebook 技术策略主管Vijay Rao 开源了全新的AI 硬件:面向AI 训练与推理的硬件系统Zion 与Kings Canyon,以及针对视频转码的Mount Shasta。这篇博客内容对此进行了详细介绍。
Facebook 的基础设施现在每月为其整个应用和服务系统上超过27 亿的人提供服务。他们的工程师设计并创建了高级、高效的系统来扩大这一基础设施,但是随着工作负载的增长,单靠通用处理器已经无法满足这些系统的需求。晶体管增长的速度已大大放缓,这就需要开发出专门的加速器和整体的系统级解决方案来提高性能、功率和效率。
为基础设施创建高效的解决方案需要共同设计优化了工作负载的硬件。为此,Facebook 一直与合作伙伴共同开发针对AI 推理、AI 训练和视频转码的解决方案。这几个都是其发展最快的服务。今天,Facebook 发布了其用于AI 训练的下一代硬件平台Zion、针对AI 推理的新定制芯片设计Kings Canyon 以及用于视频转码的Mount Shasta。
AI 硬件
AI 工作负载的使用贯穿Facebook 的架构,使其服务相关性更强,并改善用户使用服务的体验。通过大规模部署AI 模型,Facebook 每天可以提供200 万亿次推测以及超过60 亿次语言翻译。Facebook 使用35 亿多公开图像来构建或训练其AI 模型,使它们更好地识别和标记内容。AI 被应用于各种各样的服务中,帮助人们进行日常互动,并为其提供独特的个性化服务。
Facebook 上的大多数AI 流程都是通过其AI 平台FBLeaner 进行管理的,该平台包含集中处理各部分问题的工具,如特征库、训练工作流程管理以及推理机。与设计并发布到Open Compute Project(OCP)的硬件相结合,这将能够促使Facebook 大规模、高效地部署模型。从一个稳定的基础开始,Facebook 专注于创建与供应商无关的整合硬件设计,并且为实现工作效率最大化,继续坚持分解设计原则。结果就是Facebook 推出了用于工作负载训练和推理的下一代硬件。
AI 训练系统Zion
Zion 是Facebook 下一代大存储统一训练平台,设计上能够高效处理一系列神经网络,包括CNN、LSTM 和SparseNN。Zion 平台能够为其严重的工作负载提供高存储能力和带宽、灵活高速的相连、强大的计算能力。
Zion 采用了Facebook 全新的、与供应商无关的OCP 加速模块(OAM)。OAM 形状系数让Facebook 的合作伙伴(包括AMD、Haban、GraphCore 和Nvidia)可以在OCP 通用规范上开发自己的解决方案。通过单个机架使用TOR 网络转换,Zion 架构让Facebook 能够在每个平台上自由扩展到多个服务器。随着Facebook AI 训练工作负载的规模和复杂性不断增长,Zion 平台也会随之扩展。
Zion 系统分为三个部分:
8 插槽服务器
8 加速器平台
OCP 加速器模块
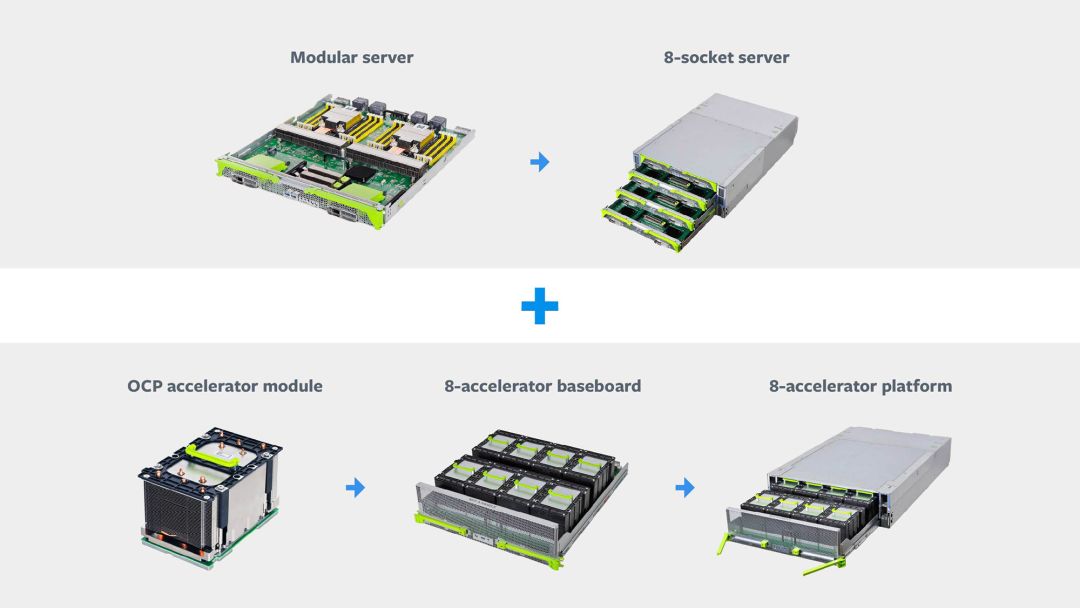
AI 训练解决方案基础模块
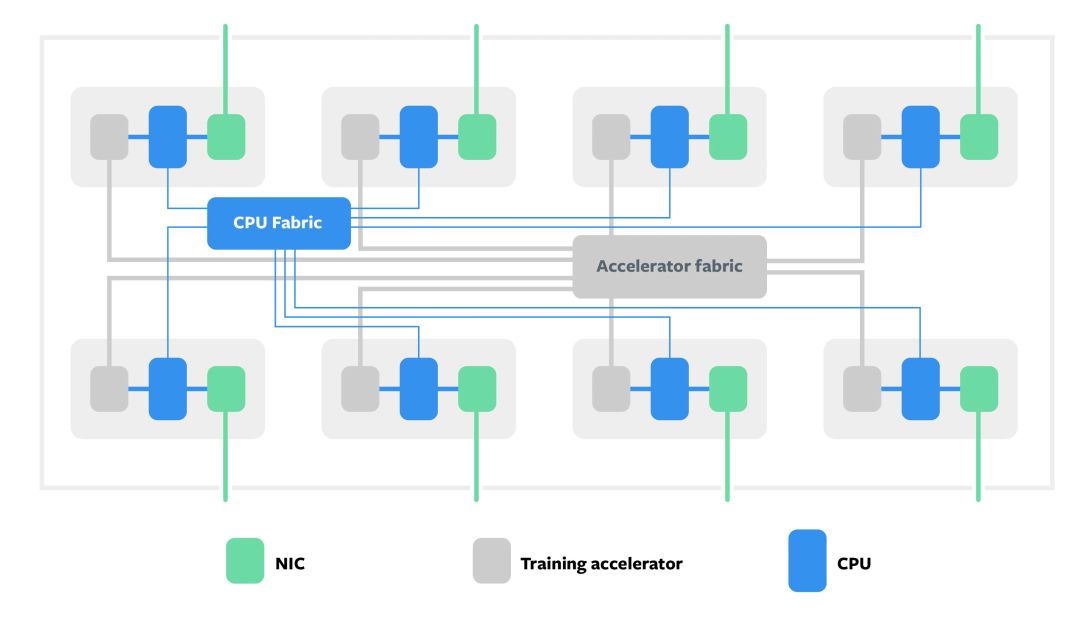
Zion 连接模块图解
Zion 将系统的内存、计算和网络密集型组件分离,使每部分都可单独扩展。该系统为8 个NUMA CPU 插槽提供了一个大型DDR 存储池,以满足工作负载存储容量密集型组件的需求,例如SparseNN 的嵌入表。对class="weapp_text_link" data-miniprogram-appid="wxf424e2f3e2f94500" data-miniprogram-path="pages/technology/technology?id=85c4b79b-6428-4184-b9bc-5beb6e2b1f3f&from=weapp" data-miniprogram-nickname="机器之心Synced" href data-miniprogram-type="text" data-miniprogram-servicetype="">CNN 或者SparseNN 密集部分这样的存储-带宽密集型和计算密集的工作负载,每个CPU 插槽都连接了OCP 加速模块。
系统有两个高速结构:连接所有CPU 的相干结构和连接所有加速器的结构。因为加速器存储带宽高但存储容量低,因此通过以这样的方式对模型进行分区来有效利用可用的总存储容量,从而使访问频率较高的数据驻留在加速器上,访问频率较低的数据驻留在具有CPU 的DDR 内存上。所有CPU 和加速器之间的计算和通信都是平衡的,并且通过高速和低速相连有效地进行。
通过Kings Canyon 执行推理
一旦我们训练完模型,就需要将其部署到生产环境中,从而处理AI 流程的数据,并响应用户的请求。这就是推理(inference)——模型对新数据执行预测的过程。推理的工作负载正急剧增加,这反映了训练工作的大量增加,目前标准CPU 服务器已经无法满足需求了。Facebook 正与Esperanto、Intel、Marvell 和Qualcomm 等多个合作伙伴合作,开发可在基础设施上部署和扩展的推理ASIC 芯片。这些芯片将为工作负载提供INT8 半精度的运算,从而获得理想的性能,同时也支持FP16 单精度的运算,从而获得更高的准确率。
版权保护: 本文由 沃派博客-沃派网 编辑,转载请保留链接: http://www.bdice.cn/html/44374.html


